



Senior Product Marketing Manager
IVR voice technology crawled along for decades, taking only occasional steps forward.
Then came smartphone voice assistants such as Siri and Cortana, and smart speakers such as Amazon Echo (powered by Alexa) and Google Home (powered by Google Assistant), bringing a digital revolution and quantum leaps in speech technology.
As customers rapidly adopted these new technologies and ways to communicate, their expectations changed dramatically. Customers now expect intelligent and effortless automated interactions—which companies will deliver only by transforming their traditional IVR systems with the latest text-to-speech voice synthesis capabilities.
Customers dread listening to a robotic voice. So companies have used human voice talent to record IVR prompts. Unfortunately, to create high-quality audio these recordings must be further enhanced, uploaded into the application, and then managed—a complicated, expensive, and time-consuming process that just isn’t viable for many scenarios. These include responding to urgent and unexpected events, such as sudden changes to markets or weather, and delivering dynamic content, such as a customer’s account balance.
Dynamic content is essential to any self-service application. It is virtually impossible to cover 100 percent of all possible values using professional voice recording, so most companies today use standard text-to-speech (TTS) voice synthesis technology. However, standard TTS offers limited voice options and subpar sound quality that comes off as muffled, buzzy, or robotic.
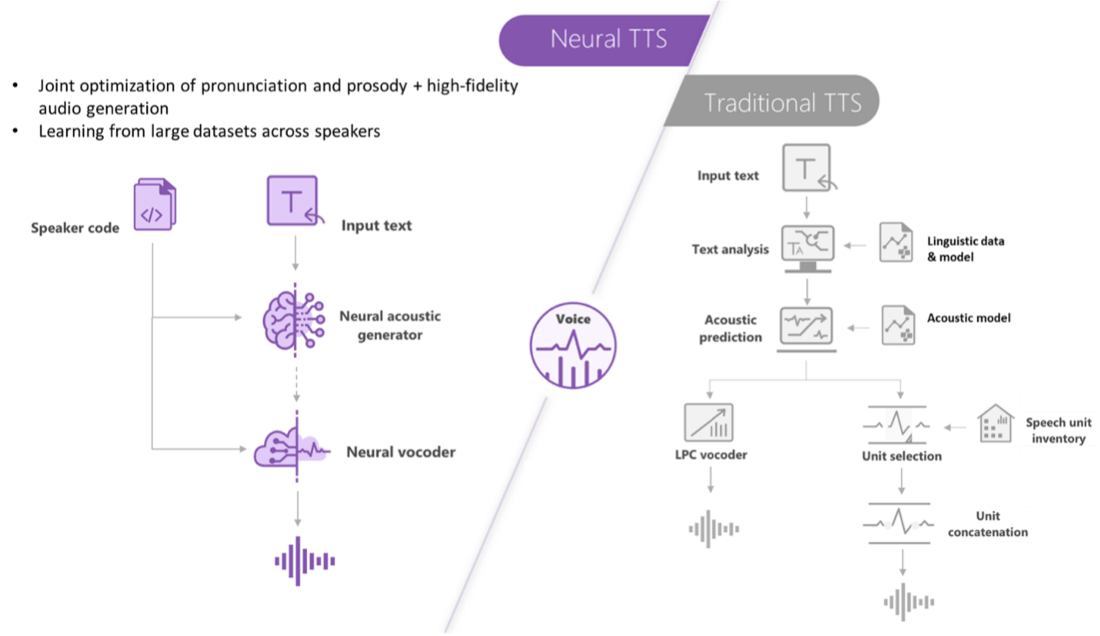
Neural text-to-speech (TTS) voice synthesis improves on standard text to speech with deep neural network (DNN) technology that matches spoken language’s stress and intonation patterns—called prosody—when synthesizing the units of speech into a computer voice. The result is humanlike, natural-sounding, high-quality voice synthesis.
For an in-depth description of how neural and standard TTS each approach prosody prediction and voice synthesis—and to see why neural TTS voice synthesis is superior to the text-to-speech synthesis offered by standard TTS—read this Microsoft Azure blog post.
“Traditional text-to-speech systems break down prosody into separate linguistic analysis and acoustic prediction steps that are governed by independent models. That can result in muffled, buzzy voice synthesis. Our neural capability does prosody prediction and voice synthesis simultaneously. The result is a more fluid and natural-sounding voice.” Source: Microsoft
The customer experience is all about human connection, and neural text-to-speech synthesis is a powerful way to make it real.
Neural text-to-speech synthesis converts text to lifelike speech on the fly without any need for voice talent recording. It makes automated conversations sound lifelike by fine-tuning pitch, inflection, intonation, and tempo.
Neural text-to-speech synthesis accelerates time to production with no need to pre-record audio files. Instead of creating or changing a message by recording or rerecording with a human voice, neural TTS prompts are dynamically generated from raw text in real time. Businesses easily build and deploy a new IVR call flow, or make changes to an existing flow, in minutes instead of days or weeks.
Delight customers with relevant, contextual prompts like “Welcome back, Stephanie. How can I help you?” or “Are you calling about the homeowner’s policy for 220 Willow Drive in Danville?” Offer a clear and crisp voice during dynamic prompts, improving customer experience.
When you need to act quickly, simply render announcements dynamically on the spot. Quickly generate prompts such as “The hurricane has changed course and is now heading away from downtown” or “We currently cannot accept payments due to a sudden outage in our payment processing system.”
Choose a voice that reflects your company brand with gender, persona, and speaking style (e.g., newscaster vs. neutral) options.
We partner with Microsoft Azure Cognitive Services to deliver industry-leading neural text-to-speech synthesis in [24]7 Voices, our modern, conversational AI IVR system that makes every interaction natural, intuitive, and efficient. [24]7 Voices is a key component of our unified, enterprise-scale voice and digital platform, [24]7.ai Engagement Cloud, which has everything you need for unparalleled customer engagement.
To learn more about how to increase self-service containment and elevate CX:
Watch the on-demand webinar: Conversational Engagement: A Clear Path from IVRs to IVAs
Read the article: Innovating the Traditional Phone Channel
Visit the web page: Modernize Your IVR with AI-Powered Conversations
![[24]7.ai Quarterly Product Release Highlights Q1](/sites/default/files/styles/medium/public/image/content/blog/product-release-july-2024-thumbnail.png)
Product Innovations and enhancements to keep our customers at the forefront of…

The Future of Insurance CX: Seamless Journeys Powered by Automation &…