You’ve likely heard the buzz surrounding ChatGPT, the latest name in AI hitting newsfeeds and newsrooms, boardrooms and watercoolers. But what exactly is it? It’s the latest in the line of Natural Language Generation (NLG) models that have been a regular feature of the AI landscape for the past few years. So why the buzz now? And what does it mean for AI chatbot companies like us who offer AI solutions?
We will try to answer these questions in this post.
What is ChatGPT?
Let’s start by understanding what ChatGPT is. GPT stands for Generative Pretrained Transformers. Let’s unpack those terms:
- Generative: This implies the model can generate text as opposed to, say, a text classifier that ingests text and produces a label.
- Pretrained: This simply means the model has already been trained on a large body of natural language data. These could be public domain datasets like the BookCorpus (originally introduced here) or information crawled from the web. The goal is a “batteries included” approach: your model already understands language, you only need to minimally fine-tune it to your specific task.
Contrast it to a “bottom-up” approach where a model is entirely trained on a specific dataset: the model sees both the language and the problem/task at the same time. In a way, pre-training decouples these two kinds of information.
- Transformers: This is a type of Neural Network architecture, that has been quite popular in the past few years. Introduced by Google in 2018, they excel at intelligently processing context to generate text or make other kinds of predictions.
You might think that using context cannot be a radically new idea – and you would be right. Most text models and architectures before and since the Transformer leverage context to various extents, but what makes them stand out is the steady stream of state-of-the-art results they have produced on a diverse set of tasks –including
Computer Vision (using
Vision Transformers)! Here’s a (massive)
catalog of all the models that Transformers have made possible.
OpenAI has released a bunch of models within the GPT family over the years – we had
the first GPT model in 2018, followed by GPT-2, 3, 3.5,
InstructGPT and
possibly GPT-4 in the near future. InstructGPT was an interesting development, since it used a technique called
Reinforcement Learning from Human Feedback (RLHF) to learn what responses are desirable, from human feedback. InstructGPT showed that RLHF not only improves the quality of generated text, but also that it can do so at much smaller sizes: in
human evaluations, OpenAI found that InstructGPT’s responses were preferred over those of the 100x larger GPT-3 model.
ChatGPT combines ideas from GPT-3.5 and InstructGPT. While GPT-3.5 gives it a reliable tried-and-tested NLG backbone, the lessons from InstructGPT, specifically using RLHF to meaningfully guide the model’s training phase, help it to produce relevant responses. And because ChatGPT is open to use for all (you can try it
here), it keeps accumulating rich human feedback data which is used to retrain the model. OpenAI keeps rolling out these improved models as and when they become available.
How good is ChatGPT? How much of it is hype?
ChatGPT is really good – and given its popularity, you probably don’t need us to tell you that. It shines in terms of both coherence and the relevance of its responses. It signals a dramatic improvement in AI-driven conversational capabilities. If you compare it to some of the early Deep Learning-based NLG models, like the original seq2seq models (as the name implies, these ingest and produce sequences of characters or words), the jump in capability is nothing short of astonishing.
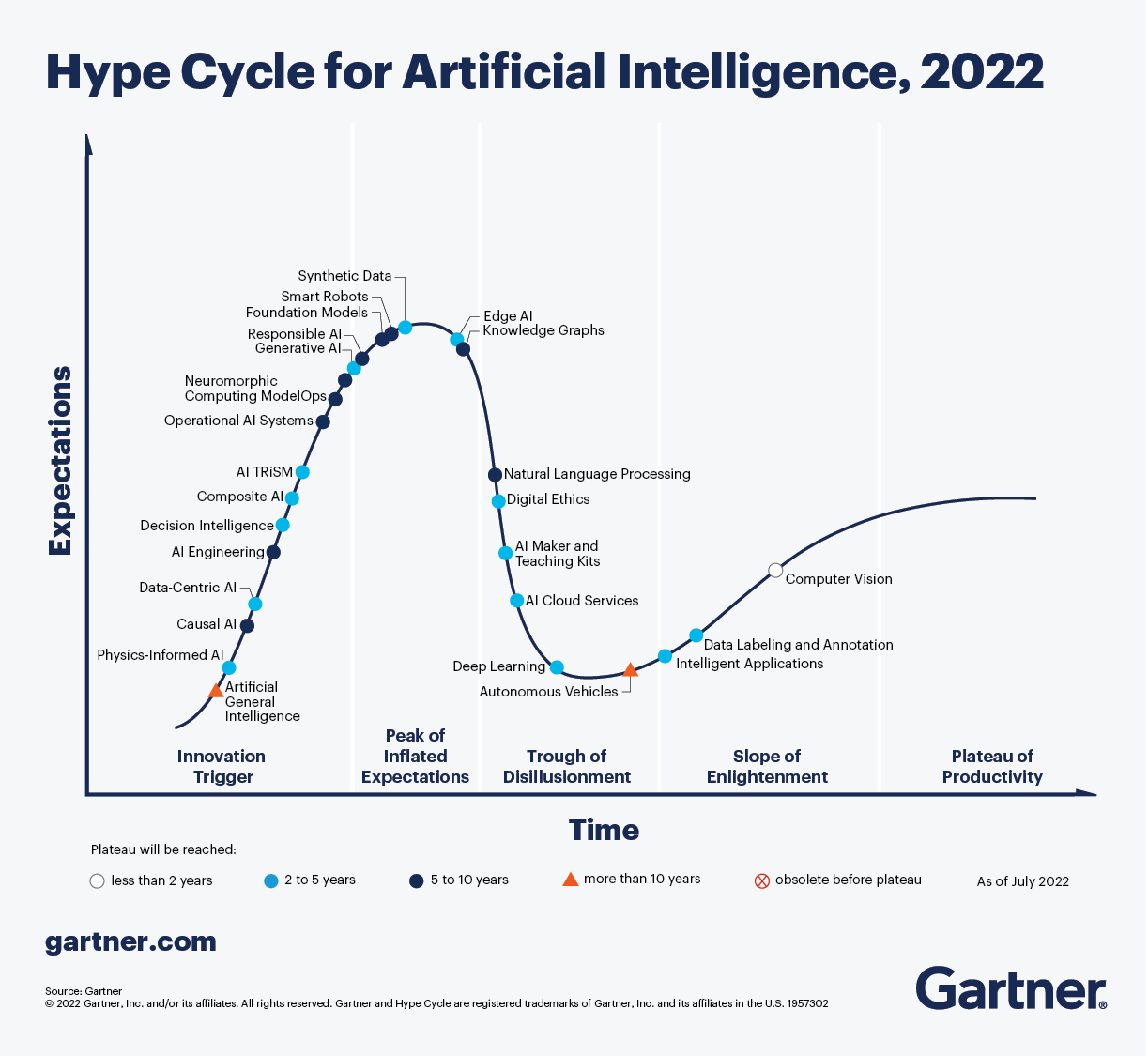
So it's not all hype. But there is some hype associated with it – which is par for the course for breakthroughs such as these. To understand this, let’s look at Gartner’s Hype Cycle chart for AI.
The general trend is:
- In the initial days, there is a surge in expectations, especially around various potential applications. This goes all the way up to the “Peak of Inflated Expectations.”
- As more people try out the idea itself or test out its applications, they are exposed to its shortcomings. A period of disenchantment follows and expectations plummet to the “Trough of Disillusionment.”
- Having seen both the good and both sides, users return with tempered expectations, and we again see a rise in popularity, but not to the initial levels. This is the “Slope of Enlightenment.”
- And finally, when the expectations match both the strengths and limitations of the innovation, it finds applications to niches where it is actually useful. This is the “Plateau of Productivity.”
To take an example, you can spot “Deep Learning” at the “Trough of Disillusionment”. The initial excitement around this field has given way to a more realistic view of its capabilities. “Computer Vision” is further along the curve and is headed towards the “Plateau of Productivity.” People know what it is good for, and how to use it in a way that exploits its strengths but does not rely on its weaknesses.
Where is ChatGPT on this curve? We believe it's a little to the left of the “Peak of Inflated Expectations” - close to where may spot “Generative AI.” We don’t know if there is a “Trough of Disillusionment” coming, or the extent of one if it arrives, but some tempering of expectations is bound to take place. This is a good segue to our next topic.
What does this mean for [24]7.ai?
The question that is most relevant to us at [24]7.ai is if ChatGPT is ready to power our conversational AI solution, AIVA. ChatGPT was built to tackle open-domain conversations, and for client-specific, goal-oriented conversations like the kind we cater to, it possesses some limitations:
- Precision: when visitors to a client’s website or IVR talk to AIVA, they expect crisp responses that resolve their problems. ChatGPT can be quite verbose.
- Goal-orientation: this is a critical part of conversations in the customer service domain. Over multiple turns in a dialogue, AIVA needs to identify the nature of the problem a visitor has and then identify an appropriate solution. We don’t have a way today to train ChatGPT for such targeted goal-oriented problem resolution.
- Flow control and design: There are instances where specific paths in the conversation flow need to be designed:
- “Blip” events like campaigns. A client launches a discount campaign next Monday and expects AIVA to answer related questions on day one. There is no time to collect data here. The campaign-related flows need to be designed.
- There may be conversation paths that are not commonly traversed. Maybe not a lot of people come in with troubles with billing – which means there is not a lot of data for these kinds of conversations – but when they do come in, we need to resolve their problems just the same. Here too, we may need to design some of the flows, possibly supported by the small amount of data we do accumulate.
- Sometimes a client might not want a chatbot to function the same way as an agent. For example, they might require that the bot gathers account related information upfront (which human agents might collect at different points in their conversation), as an added measure of security. There is no data to learn from! Such “policy-driven” flows need to be designed.
- We also need control to avoid certain conversations. Probably the most famous cautionary tale here is that of Microsoft’s Tay, which devolved into generating inflammatory tweets soon after its launch.
In our experience, an effective bot is a hybrid of both AI and design. And a Conversation Experience (CX) designer has a significant role to play in providing a smooth user- experience. Over time, we hope ChatGPT allows users to more directly shape conversation paths via fine-tuning and design.
- Client Vocabulary: Enterprise chatbots need to be sensitized to client-specific vocabulary to accurately interpret a visitor’s intentions. For example, if a visitor says “My D3050 doesn’t start anymore!” we want the chatbot to infer that they are referring to their laptop or a TV. This is typically achieved by fine-tuning or interfacing with other systems.
- Authenticity: We also want the information to be surfaced to visitors to be authentic. This is a commonly documented problem with ChatGPT – it often concocts names of books or articles.
- API integrations: A chatbot solution needs to integrate with other APIs to be effective. There are at least a couple of use-cases where this is important:
- Personalization: During a conversation you might want to inject specific bits of information into your responses. For example, if a visitor’s account ID is already known (because she is logged into her account), you might prefer the chatbot to say “Hi [Jane], how may I help you today?” instead of “Hi, how may I …".
- Transactions: Sometimes the goal of a conversation is a transaction. For example, a visitor might request to increase her credit card balance. In such cases, the capability of integrating with APIs is not optional.
ChatGPT doesn’t provide a way to integrate with APIs yet. To be fair, connecting to a larger environment has been a challenge for NLG systems in general, but there has been some promising research, such as Memory Networks and Tool Augmented language Models. For the bottom-up approach that AIVA takes – blending ML and design – such integrations are easily supported.
- Security and Privacy: It goes without saying that a system running within a corporate environment needs to be both secure and privacy aware. For example, PCI compliance is a necessity for certain types of conversations. You also need to ensure that the data a model sees is not compromised: either via infra-related vulnerabilities or through unintentional sharing of model intelligence between competitors. We hope OpenAI’s Privacy Policy expands to meet these requirements thus paving the way for a safe and secure experience.
In short, it all comes down to how finely you can control conversations, safety and the ability to connect to a larger environment, e.g., APIs, databases. These are not deficiencies in ChatGPT per se, but NLG in general. Controlled generation is hard, and we are already seeing fallouts due to this (Google’s Bard and Microsoft’s Bing AI). We don’t think we are going to see a ChatGPT-meets-AIVA buddy movie right away – but here’s hoping it is here soon!
How can NLG help our products?
What would be the impact of mature NLG, i.e., something that meets the above criteria, on our products? Before we answer that question, we would like to add a caveat: a good language model alone does not a good chatbot platform make. To have a chatbot running for years with zero downtime, that adapts to visit trends, ensures authenticity and safety, and can play well with other information sources, you need a solid foundation of good engineering, that enables you to answer questions like these:
- How does your bot scale with the population? As of writing this, OpenAI has had some outages and their API uptime is not 100% yet.
- Does it always meet a low-latency response requirement?
- Is there enough information logged that can be used to build useful reports or to perform troubleshooting?
And, also an ecosystem of AI-enabled tools that help you with various lifecycle management aspects of your chatbot:
- Is there a low/no-code tool that helps you build models quickly?
- Determine what topics are visitors discussing?
- Is your flow design tool intuitive?
- Is there is monitoring service you can look up to gauge the health of your system? This is not to say a good model is not important, but that there is a lot that goes behind the scenes in providing a seamless experience.
Getting back to the original question, we expect mature NLG models to make a difference, at least initially, in “human-in-the-loop" systems, where a user can gatekeep its limitations, etc. Some examples:
-
Conversation design: During the conversation flow design phase, a model like ChatGPT may act like a “smart assistant” to suggest appropriate chatbot responses and conversation flow paths, based on analysis of past chat data. The goals here are to increase a designer's productivity and minimize the number of iterations required to create a chatbot that is comprehensive enough to handle every potential visitor query.
- Agent Assist: In real time, a ChatGPT-like model might monitor an ongoing conversation and propose appropriate responses for use by a human agent. This reduces the cognitive load of the agent, who often is simultaneously managing multiple active conversations, thus reducing the Average Handling Time (AHT). This also helps in in homogenizing responses, leading to greater Customer Satisfaction (CSAT).
- Answers: A good NLG model would be able to ingest user-provided documents and knowledge bases, to create a helpful Q&A system, with minimal human supervision. Goal: low client onboarding time.
We already power the above solutions with our AI today – but, of course, we expect every new wave of models to potentially improve their capabilities. Fortunately, our proprietary AI platform Lumos AI, makes it simple to integrate new models. It is a “meta-stack,” composed of multiple components, that were either developed in-house or externally. Some past examples of such integrations are Deep Learning models for embeddings and the TensorFlow framework.
Our Strategy
Our strategy always has been to observe developments in the AI landscape, assess them for maturity and compatibility, and absorb them into our platform. Think of us as working on a jigsaw puzzle where the picture we are assembling remains the same – AI-powered customer service – but the pieces are rapidly changing. While we don’t want to rush to integrate new technologies right out the gate, we are not only watching this space closely – ChatGPT and other NLG offerings – but we are invested in goal-oriented NLG research ourselves. These are exciting times for language modelling. And we will keep making the best-in-class part of our solutions to power safe and meaningful conversations.